In the mention of my custom router, I talked about how Google Fiber would soon be introducing 5Gb and 8Gb service. Recently I was upgraded to the 5Gb service and… let’s just say it isn’t what I expected.
I had a feeling this would be the outcome as well.
The service overall felt snappier compared to the 2Gb service. But maintaining line speeds above 2Gb or 3Gb was proving difficult, even during off-peak hours. Running a speed test from the router using the SpeedTest CLI demonstrated this. Upload speeds would have no issue breaking 4Gb or even 5Gb, but download speeds would typically max out at 3Gb.
So what gives? In short, it’s the router itself. I just don’t think the APU can keep up with the demand. It has no issue keeping up with 2Gb service or less. But beyond 2Gb it becomes inconsistent.
But I’m not about to switch back to using Google’s router. For one that would require adding back in the 10GbE RJ45 SFP+ module, which runs hot, and the active cooling to go with it. Or using a media converter.
So instead, I need to upgrade my custom router. The big question is what platform to jump to: 990FX or X99? Now reading that question, you’re probably already shouting “How is that even up for debate?”
Current specs
Before going too far, here’s what I’m starting with.
| CPU: | AMD A8-7600 APU with Noctua NH-D9L |
| Mainboard: | Gigabyte GA-F2A88X-D3HP |
| RAM: | 16GB DDR3-1600 |
| PSU: | EVGA 650 G2 |
| Storage: | Inland Professional 128GB 2.5″ SATA SSD |
| WAN NIC: | 10Gtek X540-10G-1T-X8 10GbE RJ45 |
| LAN NIC: | Mellanox ConnectX-2 10GbE SFP+ |
| Chassis: | Silverstone GD09 |
| Operating system: | OPNsense (with latest updates as of this writing) |
Which path forward?
In a previous article about doing a platform upgrade on Nasira, I mentioned I have a 990FXA-UD3 mainboard from Gigabyte. Talking specifically about how it does its PCI-E lane assignments before revealing, ultimately, that I went with a spare X99 board for Nasira due to memory prices. And that gave the benefit of PCI-E 3.0 as well, which was important for the NVMe drive I was using as an SLOG.
For a router, PCI-Express 3.0 isn’t nearly as important so long as you pay attention to lane assignments. Though for a gigabit router, even that doesn’t matter much. Both cards were on at least 4-lanes and running at their full speeds – 5.0GT/s for both.
So if lanes aren’t the problem, that leaves the memory or processor. And there isn’t much benefit to bumping from DDR3-1600 to DDR3-1866 for this use case. The memory just isn’t going to make that much of a difference here since the memory already provides more than enough bandwidth to handle this use case.
So that leaves the processor.
990FX with FX-8320E
Compared to even an FX-8320E, the AMD A8-7600 APU is underpowered. The onboard GPU is the only benefit in this use case. The FX-8320E doesn’t provide much of a bump on clocks, starting out at 3.2GHz but boosting to 4GHz. Performance metrics put the FX-8320E as the better CPU by a significant margin. The FX-8350 would be better still, but not by much over the FX-8320E.
So while it’s the better CPU and platform on paper compared to the APU and the A88X chipset, is it enough to serve as a 5Gb router?
Well I didn’t try that. I decided to jump to the other spare X99 board instead.
Or, rather, the X99 with i7-5820k
So again you were probably asking why I was even considering the 990FX to begin with? And it’s simply because I had one lying around not being used. Specifically the Sabertooth 990FX from Nasira still assembled with its 32GB DDR3-1600 ECC, FX-8350, and 92mm Noctua cooler. And I actually have a few 990FX boards not being used.
But I also had the Sabertooth X99 board that was in Mira still mostly assembled. It hadn’t been used in a while and just never torn down, so it was relatively easy to migrate for this.
So why the leap to the X99 over the 990FX? In short, it’s the specifications for the official pfSense and OPNsense appliances.
The Netgate 1537 and 1541 on the pfSense front are built using the Xeon-D D-1537 and D-1541, respectively, which are 8-core/16-thread processors, and DDR4 RAM. Both are rated for over 18Gb throughput.
And OPNsense’s appliances use either quad-core or better AMD Ryzen Embedded or Epyc processors. The DEC740 uses a 4-core/8-thread Ryzen with only 4GB DDR4, while the slightly better DEC750 doubles the RAM. Both are rated for 10Gb throughput.
But their DEC695 has a 4-core/4-thread AMD G-series processor and DDR3 RAM, and is rated for only 3.3Gb of throughput. Hmm… that sounds very familiar…
Quad-channel memory is where the X99 platform wins out, compared to dual-channel support for the aforementioned Ryzen and Xeon CPUs. But to get started, I ran with dual-channel since two sticks of DDR4-3200 is all I had available at the moment. If everything worked out, that would be replaced with 4x4GB for quad-channel RAM and a Xeon E5-2667 v4, which should yield overkill performance.

Here’s the temporary specs:
| CPU: | Intel i7-5820k with NZXT Kraken M22 |
| Mainboard: | ASUS Sabertooth X99 |
| Memory: | 16GB (2x8GB) DDR4-3200 running at XMP |
Side note: I was able to move the SSD onto the new platform without having to reinstall OPNsense. It booted without issue. I still backed up the configuration before starting just. in. case.
So was this able to more consistently sustain 5Gb? Oh yeah!
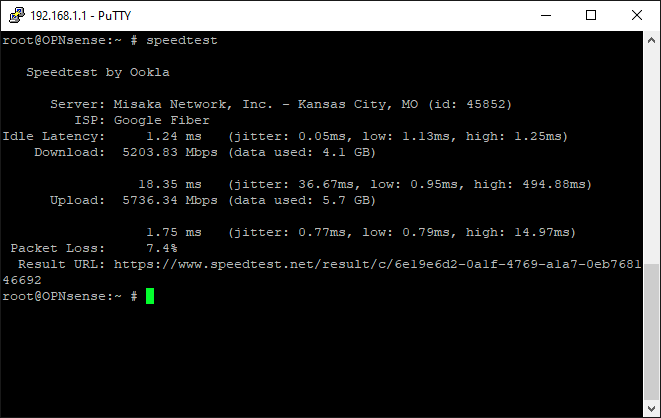
One rather odd thing I noticed with the speed test, both on the old and new router setups: when trying to speed test against Google Fiber’s server, it capped out at 2Gb. But in talking to the Misaka Network server, shown in the screenshot, it now consistently gets 5Gb at the router.
Note: The command-line tool allows you to specify a server to test against. So going forward with my speed testing from the router, I’ll need to remember that.
With the AMD APU, it wasn’t getting close. And the FX-8320E or FX-8350 on the 990FX probably would’ve done better, but clearly it was best that I jumped right to the X99 board.
So what does this mean going forward?
Road forward
So with the outstanding test results, this will be getting a few hardware changes.
The CPU and memory are the major ones, and the mainboard will also get changed out. Something about either the processor or mainboard isn’t working right, and none of the memory slots to the left of the CPU are working – as the image above shows. This tells me it’s the mainboard, the CPU socket specifically (e.g. bent pins), but it could be the CPU as well.
Either way it means I can’t run quad-channel memory. And while the above speed test shows that quad-channel memory isn’t needed, I’d still rather have it, honestly.
But I have an X99 mainboard and Xeon processor on the way which will become the new router. Quad-channel memory is the more important detail here since Xeons do not support XMP. That does mean saving money on the memory, though, since DDR4-2400 is less expensive.
The Xeon on the way is the aforementioned E5-2667 v4. That’s a 40-lane CPU with 8-cores and 16-threads. Definitely overkill and I’m not going to see any performance improvement compared to the i7-5820k. As mentioned, it does not support XMP, so the fastest RAM I’ll be able to run is DDR4-2400. But in quad-channel.
The Xeon does also allow me to use ECC RAM, and the mainboard that is on the way supports it. While the router chugs along perfectly fine with non-ECC RAM, ECC is just going to be better given the much higher bandwidth this router needs to support.






You must be logged in to post a comment.